参加CCKS2017 Task_2有感

总结一下参加CCKS2017 Task_2的感想和经验
前言&简介
全国知识图谱与语义计算大会(CCKS, China Conference on Knowledge Graph and Semantic Computing),具体介绍可以参见官网。本次会议共有两个Task:
- Task_1: 问题命名实体识别和链接(QEDL, Question Entity Discovery and Linking)
- Task_2: 电子病历命名实体识别(CNER, Clinical Named Entity Recognition)
我们参加的是Task_2,与我们现在在做的医学NLP比较相关,我之前也做过一些实体抽取的工作,不过大多是基于规则的方法。
过程
竞赛任务应该是5月份放出来的,最开始给我们的示例数据是包含嵌套实体的例子,由于竞赛组织者的标注比较随意,标注存在很多不一致的地方,但我们还是做了数据转换的工作,首先转换成MAE(一个标注工具)能处理的格式,企图对数据进行标注修正。然后把数据转换成CONLL格式,用于后面的训练和测试。但是,经过多次反馈协商,最后组织者放出来的数据都是非嵌套实体的,一致性也比之前的示例数据要好,同时组织者还给出了较多的未标注数据。
Model
这次用的model是比较传统的深度学习模型,Bidirctional RNN-CRF,如下图所示。这个模型在很多的NLP任务上都取得了很好的表现,当然我也做了一些改进。因为之前从来没有接触过深度学习,更没有实现过深度学习模型,我参考了github上的一个中文NER的项目,这个项目也是用的前面所说的基础模型,在人民日报的数据集上取得了比较好的performance,作者用的是Tensorflow实现。因为作者的代码写得比较清楚,我把所有代码通读了几遍,理解了基本逻辑,数据输入格式,特征加入等,然后基于我们的数据实现了一下,发现效果还可以。在实现了基本模型之后,我就开始了调参,还好公司的电脑比较给力,模型跑得相对较快,选出了最优参数。在此期间,我也读了一些基于深度学习的中文NLP的工作,想借鉴一些方法,当然有些模型比较复杂,实现这些模型也超出了我的能力。最终实现了一下此论文中的character representation的方法,然后加入了分词,词性,字典等特征,最后对分模型和总模型的结果做了一个整合得到最终结果。在本次竞赛中拿到第4名的成绩,参见官网。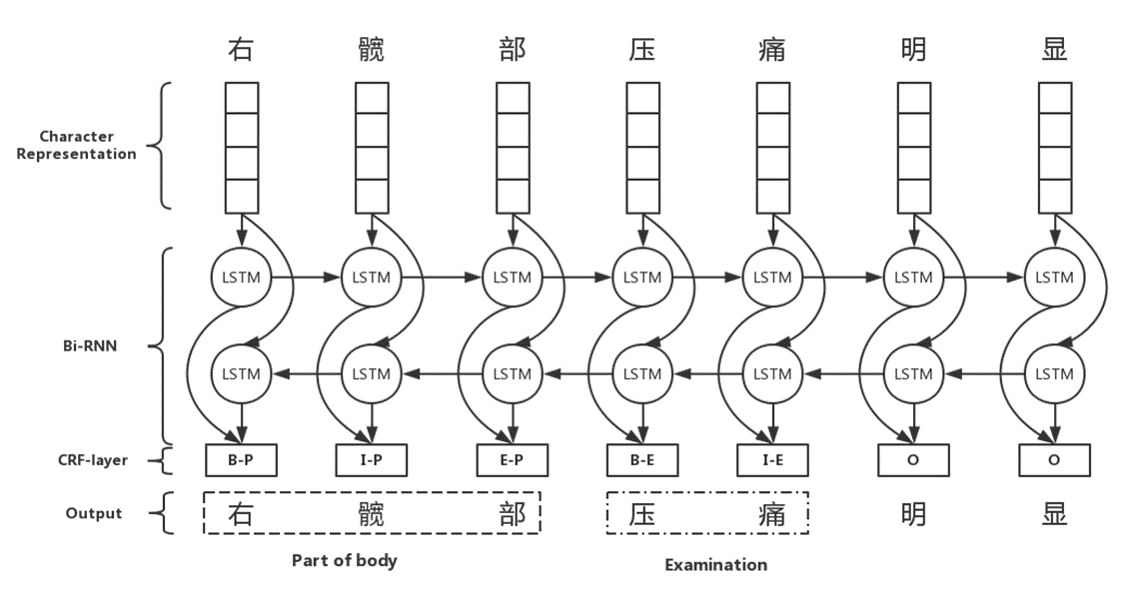
Future Work
- 探索新的模型,比如不同的character representation方法。
- 充分利用未标注数据,现在未标注数据只用在了word embedding的训练中,可以探索一些semi-supervised和active learning的方法来充分利用未标注数据。
- 把这个模型用在已有的或者新的任务上,改变大量依赖规则的现状。
感想&后记
这次是我自己第二次参加NLP方面的竞赛,去年的CEGS N-GRID Shared-Tasks作为参与者,今年作为主要完成者,差别还是挺大的。有几点感想:
- 首先,在参加这种竞赛的时候,还是要做好分工合作,这方面我觉得自己还是做的不好,绝大部分的工作都是自己完成,从最开始的数据转换,方法调研,代码实现,参数调校,论文撰写。当然其中也得到了他人的帮助,在与公司同事的交流讨论中,也产生了许多灵感,在此也十分感谢他们。希望以后自己在这方面可以做的更好吧。
- 其次,就是上面也说过的一定要多读相关文献,有个积累,然后多交流,多讨论,会有意想不到的收获。
- 最后就是代码功力,要有用代码实现方法的能力。
已经把竞赛评测论文提交了,
希望这次可以被接收吧,文章经过小修,已经被接收,还被邀请现场做Presentation,班门弄斧啊,有点紧张。
最后附上我的总结,里面有对方法和数据更详细的介绍。
本文标题: 参加CCKS2017 Task_2有感
原始链接: https://oyeblog.com/2017/ccks2017/
发布时间: 2017年09月12日 - 19时07分
最后更新: 2023年10月22日 - 15时25分
版权声明: 本站文章均采用CC BY-NC-SA 4.0协议进行许可。转载请注明出处!