Reinforcement Learning for Relation Classification from Noisy Data

这篇文章是Reinforcement Learning在NLP方面的应用,具体是用在有噪音训练集的实体关系分类问题上,已经被AAAI 2018录用,作者之前也在PaperWeekly分享过了,最近一个前同事提到Reinforcement Learning应该会是NLP的下一个热点,想想应该也是这么回事,就像之前的Attention机制一样。因此在了解了Reinforcement Learning的基本概念之后,又把这篇文章细读一遍。
链接:Reinforcement Learning for Relation Classification from Noisy Data
摘要
现有的关系分类方法主要依赖于距离监督(distant supervision),主要的假设是假如有一组句子都提到了一个实体对,那么这些句子就都描述了这个实体对的一个关系(我觉得可能就是和共现差不多吧)。这些方法一般都是在句子集的层面进行分类,而不能把关系和句子一一对应起来,造成这个问题的主要原因是标注数据集里有噪声数据。作者在这篇文章里提出了一种新的方法,这种方法可以在有噪声的数据上做到句子层面的关系分类。这个模型有两个组成部分:实例选取器(instance selector)和关系分类器(relation classifier)。实例选取器用强化学习的方法选取高质量的句子,并传递给关系分类器,关系分类器在句子层面作出预测,并反馈给实例选取器。这两个模块共同训练、优化。实验结果表明这样的方法可以有效处理训练数据中的噪声,从而在句子层面的关系分类上取得更好的performance。
简介
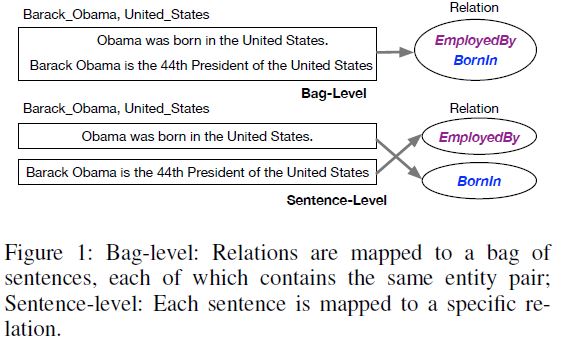
为解决标注数据含噪声的问题,现有的Bag Level的关系分类方法有两个缺陷:1. 不能处理句子级别的关系分类; 2. 假如‘Bag’中的所有句子都是噪声句子,对模型的影响很大。下图是对第一个缺陷的解释说明,‘Bag-Level’也就是relation的label是给Bag的,这一组句子包含同一个实体对,描述了哪些关系,而‘Sentence-Level’的relation label是给Sentence的,也就是对每一个句子指定一个关系类型。造成第二个缺陷的原因是,即使‘Bag’中所有句子都是噪声(也就是这些句子都没有描述某个关系),模型也会选取至少一个句子,认为选取的句子描述了某个关系,进而基于这些句子进行模型训练,而且假如标注集只是简单基于距离监督得到,这样的情况是很常见的,因此这样训练得到的分类模型的performance肯定会下降。
为了解决上述的两个缺陷,作者提出加入实例选取器,并将其转换成一个强化学习问题来解决。因为这个选取器有以下两个特征:首先,这个句子选取是一个反复试错(trial-and-error-search)的过程,需要从分类器得到对选取的句子质量的反馈(reward);其次,上述的反馈只能在整个挑选过程结束之后才能得到,因此反馈是滞后(delayed)的。这两点都非常符合强化学习的特点。
模型
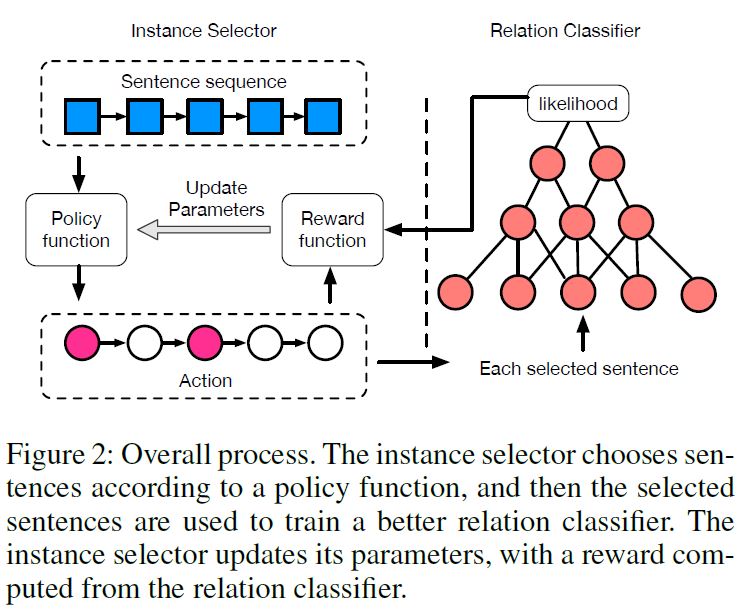
上图是整个模型的框架,由Instance Selector和Relation Classifier两部分组成,下面具体介绍两部分。
Instance Selector
因为Instance Selector是当作强化学习问题处理,因此policy function的更新会滞后,为了加快更新速度,作者采用了把所有句子分成$N$个Bag的做法,即$B={B^1, B^2,\cdots, B^N}$。对于每个$B^k$,都包含同一个实体对,而且标注的关系都是$r^k$,虽然这个标注可能是有噪声的(不准确的)。之后的训练都是以一个Bag为单位进行操作。
下面就要介绍作为强化学习,State、Action、Reward的定义。
- State State $s_i$ 包含了以下三部分信息:1.当前句子的向量表示,这个向量表示由关系分类器里CNN的非线性输出层得到;2.被选的句子集合的矩阵表示,这个由被选句子的向量表示取平均得到;3.句子中实体对的矩阵表示,这个从预训练的知识图谱embeddings得到,这个embeddings是在Freebase上采用TransE模型训练得到。
- Action action $a_i \in {0, 1}$表示是否应该选取第$i$个句子,$a_i$的取值由policy function得到,具体定义如下:
$\pi_\Theta(s_i, a_i) = a_i\sigma(W*F(s_i)+b)+(1-a_i)(1-\sigma(W*F(s_i)+b))$
这里的$\sigma(.)$是sigmoid函数。 - Reward reward由基于CNN的分类器反馈得到,计算所选的句子集合$\hat B$的likelihood,假设所选的句子集合是空集,则用所有句子的平均likelihood来计算,这应该是文章能够有效选出噪声数据的关键之一。
Relation Classifier
文章用的分类模型比较简单,也是目前效果比较好的CNN,包括输入层,卷积层,max-pooling层。
- 输入层 对于每个词的表示分为两部分,一部分是word2vec训练得到的embedding,另一部分是position embedding,这个position embedding其实是两个固定长度的向量,分别用来表示某个词到关系里的两个实体的距离,具体可以参考中科院这篇文章。
- 参数设置
| para | value |
|---|---|
| word embedding | 50 |
| position embedding | 5 |
| learning rate | 0.02 |
| dropout | 0.5 |
| convolution window | 3 |
试验
- 数据集 数据集来自New York Times (NYT),里面包含了39528个不重复的实体和53个不重复的关系类别,具体数据如下:
| sentence | entity pairs | relation facts | |
|---|---|---|---|
| training set | 522611 | 281270 | 18252 |
| test set | 172448 | 96678 | 1950 |
- 评价方式 因为本身数据集是有噪音的,所以作者随机选取了300个句子,人工标注,然后在这些句子上做评测,评测包括Accuracy和Macro F-value。设定的baseline包括:CNN、CNN+Max(每个bag里选一个认为正确的句子)、CNN+ATT(加入attention机制,降低噪声数据的权重)。
训练过程

ALGORITHM 1描述的是整体训练过程,也就是先预训练CNN分类模型,使得$log p(r_i|x_i)$最大,然后固定CNN分类器,预训练policy network,最后联合训练两个模型直至收敛。
ALGORITHM 2描述的是具体怎么实现联合训练,对于每一次的epoch,分为N个word bag,对于每个$B_i$,在计算完reward之后实例选取器的参数要更新一次,而CNN分类器的参数只有在整个epoch结束才会更新。
结果
因为后两个模型是bag level的,所以在评价的时候是把一个句子当成一个bag来处理的,最终结果如下: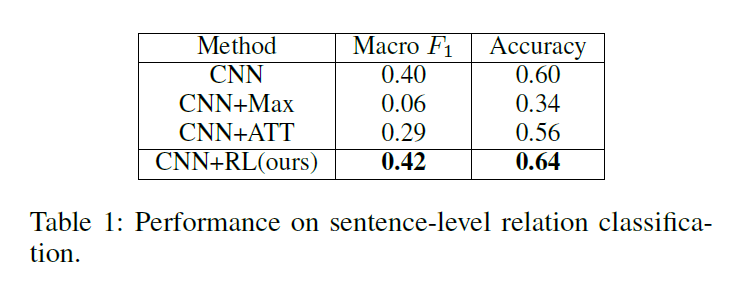
可以看出文章的模型取得最好的performance,而且句子层次的模型相比较于bag层次的模型,在这个评测中表现更好,这也是理所当然。
附加分析
分别对实例选取器和关系分类器作了分析:
- 分析加入实例选取器是否对performance提高有帮助(方法:在原始数据和选取出来的数据上分别训练模型)。
- 评价了选取器的accuracy(方法:随机选取300个句子,人工判断,最终的accuracy达到(54+177)/300=74%)。
- 比较了强化学习机制和贪婪机制(greedy selection)之间的差异(方法:所谓贪婪机制就是把强化学习机制改成选取CNN中likelihood最大的N个句子,当然这个N与强化学习机制选出的句子数目一致)。
- 验证选取器是否能区分出那些全是噪声数据的bag(方法:随机选取100个模型认为是全噪声的bag,其中有86%真的是全噪声的bag,可以证明模型把绝大多数的全噪声bag过滤了)。
思考
- 第一次阅读强化学习用在NLP上的文献,大致了解强化学习的基本思想,看到强化学习在NLP领域是有所作为的。
- 模型的State表示是由3部分组成,分别包含句子、句子集合、实体对的信息,这个State表示是否可以改变,是不是越复杂越好,包含的信息越多越好,这些应该会在下面的工作中有探索。
- 本篇文章设定的Action比较简单,但是这个Action确实是结合实际需要提出的,我不太明白是否Action设定更加复杂之后会不会对模型的performance有影响。
- 这篇工作是基于噪声数据做的,现在NLP在实际应用中,标注数据的不足、质量不高是比较大的问题,假设我们能用比较简单但是准确率不太高的方式预标注,再加入强化学习机制做模型训练,也许可以解决标注不足的问题。
- 可以探索更多能够加入强化学习机制的NLP任务,而不是仅限于噪声数据筛选这一项,比如本文同实验室的另一篇AAAI 2018的文章Learning Structured Representation for Text Classification via Reinforcement Learning,这篇文章也是要解决文本分类问题,但是角度又不一样了,是用Reinforcement Learning学习结构化表示来提高分类效果,而在强化学习上又分为两种:删去非关键词和切分词组,具体可以查看文章。
本文标题: Reinforcement Learning for Relation Classification from Noisy Data
原始链接: https://oyeblog.com/2017/paper_1_RL/
发布时间: 2017年12月12日 - 19时11分
最后更新: 2023年10月22日 - 15时17分
版权声明: 本站文章均采用CC BY-NC-SA 4.0协议进行许可。转载请注明出处!